Do you agree that regardless of your chosen business strategy and organizational culture, the drive for efficiency has always been the common goal? Well let’s figure out how to avoid operational efficiency plateaus.
Say hello to your operational efficiency plateau
Over the past years, pretty much all approaches have chosen their battles, defining the goals and drive for improvement. And in the end, it does not matter if this results from a dedicated project, an excellence program or a benchmark initiative. Targets need to be defined all the time, and if work gets done properly, you will drive performance toward your objectives.
With a few rounds of identifying opportunities, running improvement initiatives and changing your business, you will get a hang of it. You need to keep driving continuous improvement, report successful missions, standardize, etc. But sooner or later, you will find that the overall business outcome stagnates. Since the past has shown that the way improvement has been approached was very effective, many leaders reacted by increasing the number of initiatives. Something like: “Do more, do harder!”
But then frustration grows when realizing that increased efforts do not necessarily demonstrate any significant improvement. So, that is when it is time to say hello to your efficiency plateau! While in the “good days of improvement,” you kept celebrating your successes, now it’s time to “find the bug.” Whether you like it or not, that is when the blame comes in: the one of demotivation, changing people, etc.
From improvement building to improvement destruction
That being said, let’s now sit back and continue reading as I’m about to explain what is happening.
Over years—sometimes decades—the method has been successful. But why does it not work anymore? It is not that improvement methodologies do not work anymore. Lean, Six Sigma, and their siblings are as powerful as they were all along. But while we were continuously improving, we have reduced the “non-value adding” in our organization over time. At the earlier stages of improvement, every initiative has taken away some of the inefficiencies and improved the overall outcome. Your operations were packed with muscles. But we keep throwing new initiatives to keep on cutting “fat.” Obviously, new projects start contracting and hence compete with previous improvements. In other words, we start destroying improvements that we built before. Many of your achievements have names and faces tagged to them. And hence we must not be surprised that competing for improvement naturally drives competition between individuals.
Time to step up and breakthrough
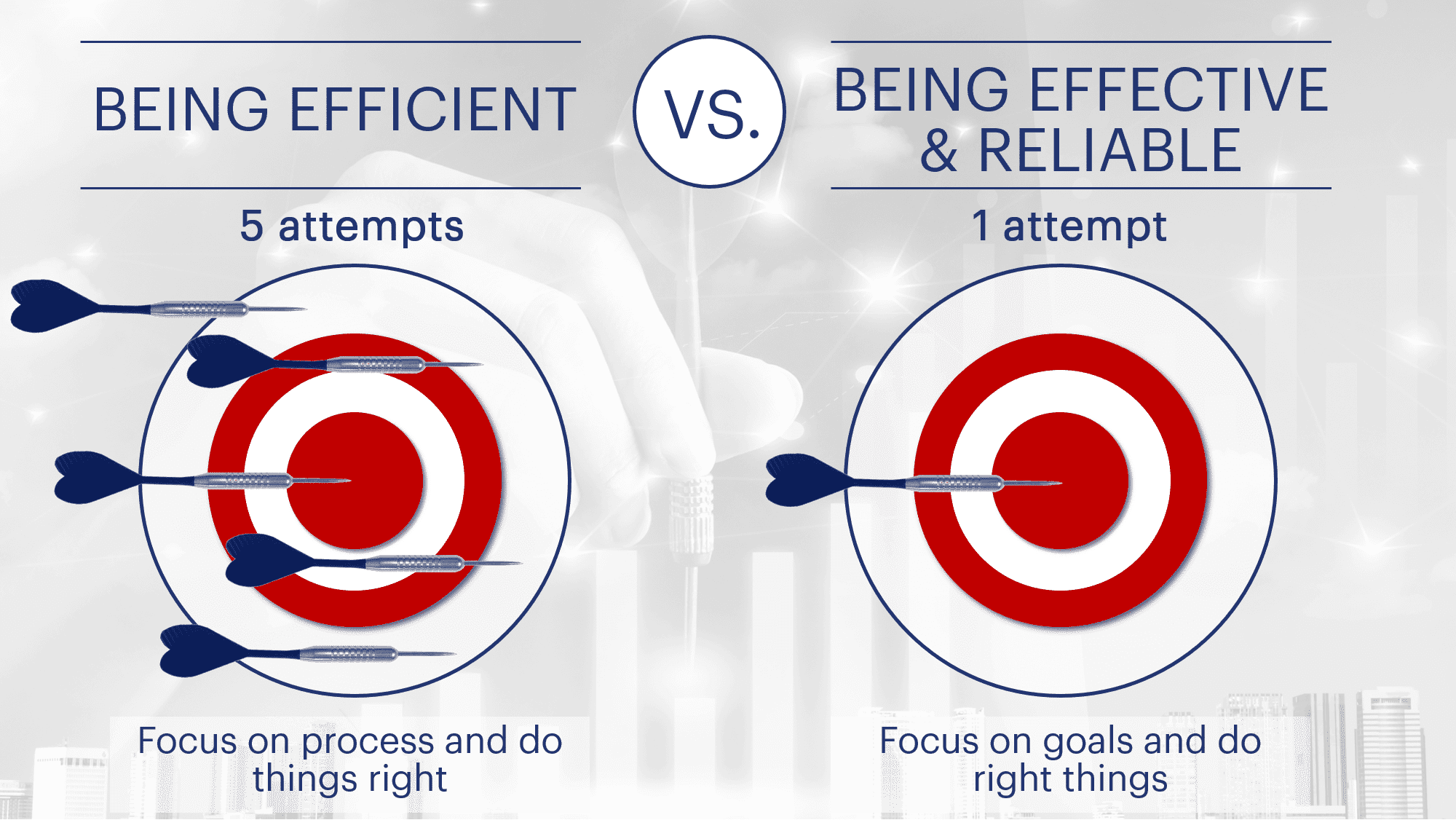
Every unit in your operations runs on targets, and shiny KPI presentations covered in green. But what about your outbound performance? Why is this not the sum of your departmental performances? Why is it not stable, solid or reliable?
The truth is rather trivial: your outbound performance is determined by the sum of all individual misses at the departmental level, where one distortion will heavily impact the outbound performance and the reliability you can perform at. Departmental failure cascades on following the downstream process. If the adjacent departments “play by the rules,” we pass on the initial delay. This is, in most cases, the least damage that happens. As soon as you will try to compensate for upstream misses further down the value chain, you will disrupt the “clockwork” in another department. It does not matter if the attempts to compensate for an upstream issue are initiated at the departmental level or by planning/scheduling. Typically, that is the time when a lot more troubles arise than when you started. And the more you try to fix issues, the newer problems trigger off.
So, what would the department heads be expected to do? Previously, you probably have tuned departments on efficiency: process maximum volume on minimum investment (asset) at the lowest expense (FTE). You have taken away all the slack, and usually, you did not find an item called “recovery capacity” in the budgets. The concept of recovery capacity sounds like a buffer or reserve. However, these terms are counterintuitive to the mindset of efficiency or cost reduction. Recovery capacity is traded in rather quickly when it is budget time. So, you incorporated the capacity that you need and covered it: the concepts of efficiency factors, capacity utilization rates, etc., come in very useful to protect that capacity without labeling it spare.
Nevertheless, since we do not transparently deal with recovery capacity, we also do not have recovery processes or procedures. We might find them implicitly at the departmental level. Priority lists, alignment meetings and “criticalities” are some of the typical constructs that get established. At the end-to-end level of an operation, we typically find escalation procedures for “critical” or “system-relevant” problems. Usually, you do not find processes in place at the end-to-end level to deal with the day-to-day variations.
Toward breaking those efficiency plateaus
So, we believe you need to start breaking this vicious circle of your supply chain’s operational efficiency plateaus. While on one side, we request each department to operate reliably according to the agreed service level, you need to ensure that as an integrated process, you do load parts of the organization with work that is not covered by the service-level agreed. Operational departments have a native pace—which can be improved—step changed, or (re)-designed. But at any given moment, a native department pace is given and needs to be reflected in the agreed service level and adhered to.
So, your end-to-end processes need to be tuned in with the native pace of the departments. Having departmental SLAs aligned with the processing capability and capacities of your processing departments, AND respecting the native operations cadence resulting in it, will build the base for a reliable end-to-end output, which will result in that change that you were looking for within another efficiency project. It sounds trivial, of course, but what to do with variability? However big our efforts, there will always be something not going according to the plan. A material missing, artwork process delayed, customer order change, machine fails, you name it!
That’s why you need to install a process to deal with exceptions that do not follow the native cadence. The exception-handling process is crucial for two reasons: First of all, to have a procedure to manage the order that deviates from its designed process. But even more important is to protect operations from getting pressurized with excessive demand to complete processing steps at a shorter than native pace. The trick is to isolate the capacity to manage exceptions without impacting the standard flow and without losing processing capacity. Individual concepts can be built for departments following their capabilities and constraints.
Calibrating lead times with native pace, aligning your product end-to-end lead-time design, protecting your standard operations flow and isolating exception handling. That’s the step change to break the plateau.
Interested to discover more? Get in touch!